From Prompts to Deployment: Auto-Curated
Domain-Specific Dataset Generation via Diffusion Models
Winter Conference on Applications of Computer Vision Workshop (WACVW), 2026
Dongsik Yoon, Jongeun Kim
HDC LABS
Abstract
In this paper, we present an automated pipeline for generating domain-specific synthetic datasets with diffusion models, addressing the distribution shift between pre-trained models and real-world deployment environments.
Our three-stage framework first synthesizes target objects within domain-specific backgrounds through controlled inpainting. The generated outputs are then validated via a multi-modal assessment that integrates object detection, aesthetic scoring, and vision–language alignment.
Finally, a user-preference classifier is employed to capture subjective selection criteria. This pipeline enables the efficient construction of high-quality, deployable datasets while reducing reliance on extensive real-world data collection.
Proposed Methods
Our automated dataset generation pipeline has two prerequisites:
- Domain-specific background images: scenes that are intrinsically difficult to collect or tied to a specific site (e.g., underground parking lots, elevator CCTV views, and home security camera footage). Because these images constitute the backgrounds in which the model will operate in real-world settings, we recognize that the number of obtainable images may be limited.
- Target object: the object to be synthesized within the given domain context. While these objects are typically common and could feasibly appear in domain images, we focus on natural object--scene combinations that are scarce in publicly available datasets (e.g., underground parking lot with a fire, elevator CCTV viewpoint with a dog, robot vacuum cleaners in home security footage).
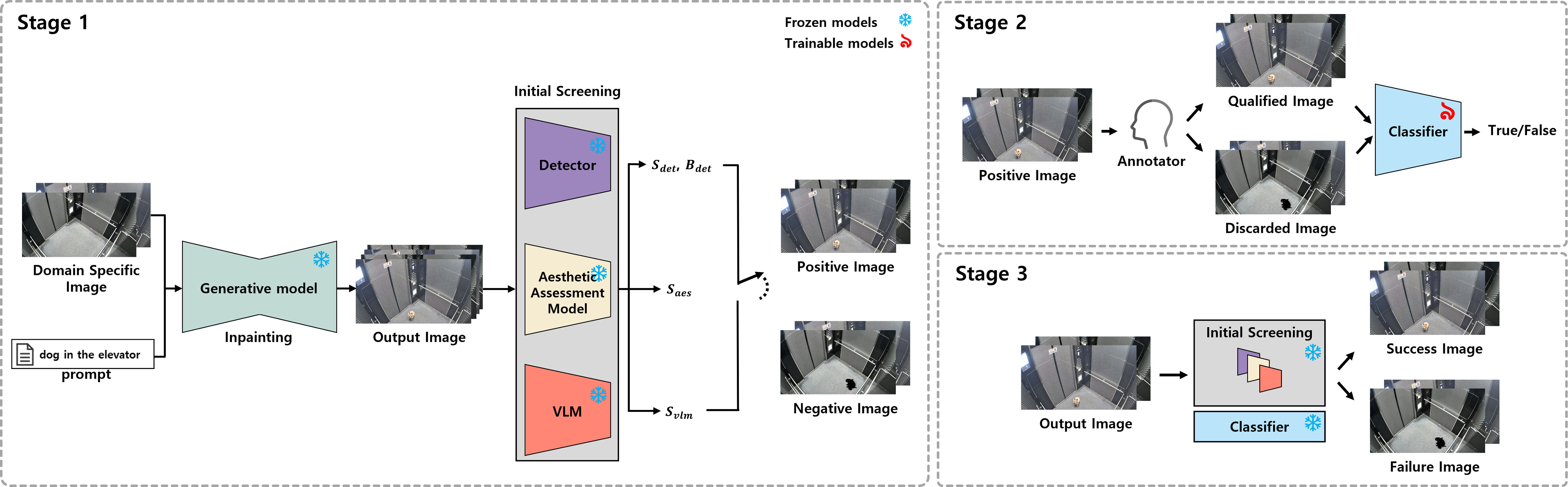
Overview of the proposed three-stage, diffusion-based dataset generation and auto-curation pipeline.
Accepted samples

Success image that passes all three stages, demonstrating target object synthesis within a domain-specific background.
Rejected samples

Negative images that failed object synthesis in Stage 1 due to low detection and aesthetics scores.

Discarded images rejected in Stage 2 due to poor viewpoint/pose from annotators despite successful object synthesis.