Reference Guided Image Inpainting using Facial Attributes
British Machine Vision Conference (BMVC), 2021
Dongsik Yoon1, Jeong-gi Kwak1, Yuanming Li1, David K Han2, Youngsaeng Jin1, Hanseok Ko1
1Korea University, 2Drexel University

Overview of proposed reference guided facial image inpainting
Abstract
Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results.
To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks.
Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Proposed Methods
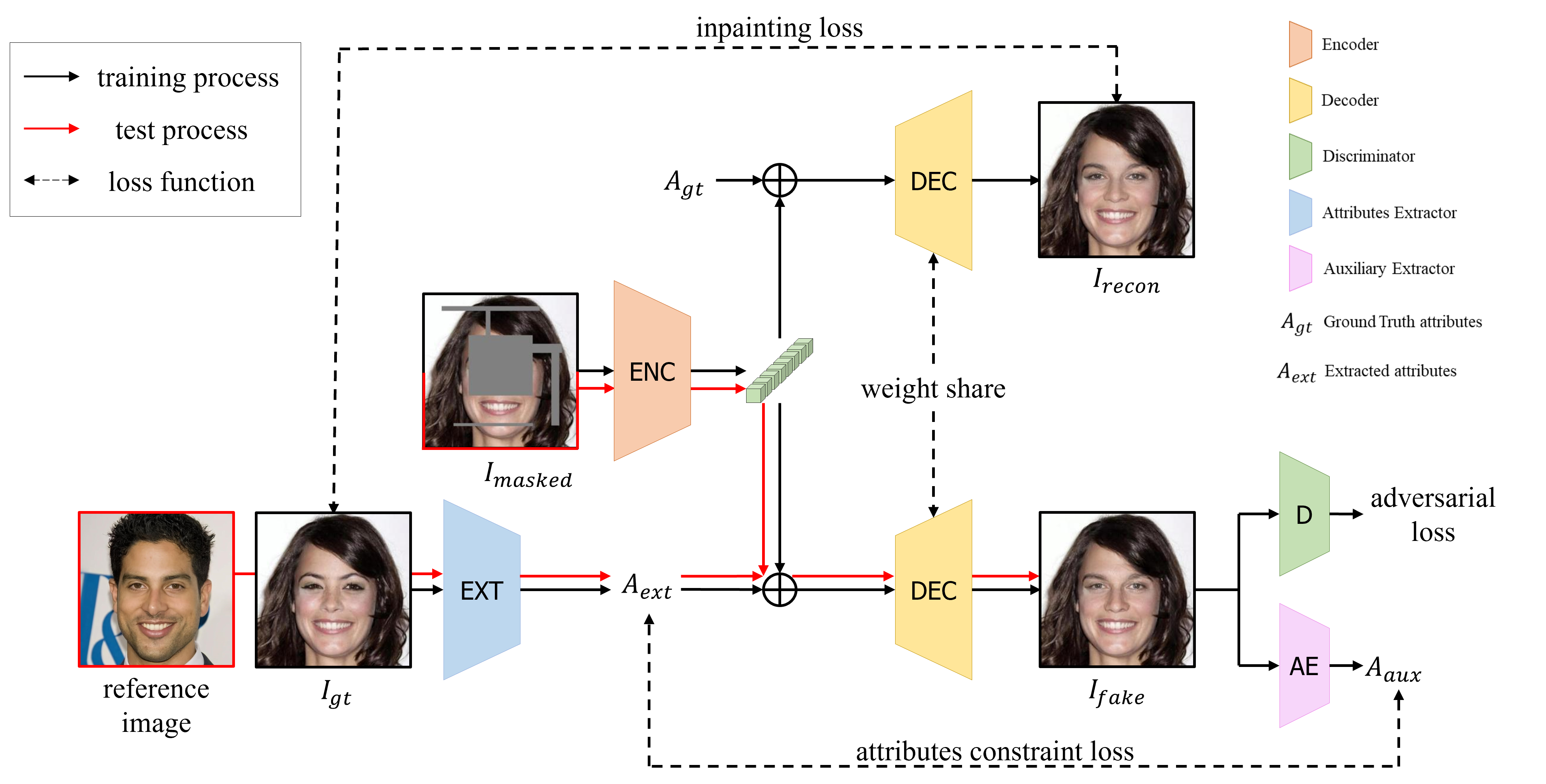
As shown in this figure, our architecture consists of four models: a generator, a discriminator, an attribute extractor, and an auxiliary extractor. Imasked and M are the input of G, we omit M in this figure to express clearly our framework. For the test stage(red line), the user extract desired attributes using our attributes extractor to a reference image.
Quantitative Comparison

This figure shows images generated by the proposed method with those generated by the other methods. Our model performed better than all the others in terms of the generated image quality and plausibility. We adopt the ground truth attributes to only evaluate the quality of the image inpainting task of our model. In our approach, despite the large irregular holes, facial structures are well preserved.

Pluralistic qualitative comparison with state-of-the-art methods with PIC, PDGAN, and Ours.

Figure shows images generated by manipulating each attribute from the positive and to the negative extremes. Our method successfully delivers plausible images according to the given mask shapes and attributes of varying degrees.