Manipulation of Age Variation
Using StyleGAN Inversion and Fine-Tuning
IEEE Access, 2023
Dongsik Yoon, Jineui Kim, Vincent Lorant, Sungku Kang
Metaverse Entertainment

Overview of proposed reference guided facial image inpainting
Abstract
Recent advancements in deep learning have yielded significant developments in age manipulation techniques in the field of computer vision. To handle this task, recent approaches using generative adversarial networks latent space transformation or image-to-image based techniques have been developed. However, such methods are limited in terms of preserving the facial identity of the subject and recovering background details during lifelong age variation.
To address these limitations, this paper presents a novel framework to manipulate the age of subjects in photos. The proposed framework involves two main steps, i.e., age manipulation and StyleGAN fine-tuning. In the first step, the iterative ReStyle StyleGAN inversion technique discovers a latent vector that is most similar to the input image, and which is used to train an age manipulation encoder. In the second step, a StyleGAN fine-tuning process is used to reconstruct the details lost in the images synthesized using the StyleGAN generator during the age manipulation. To preserve substructures, e.g., backgrounds, we optimize the loss function using facial masks generated from the original and age-manipulated images. The proposed framework is compatible with various StyleGAN based techniques, e.g., stylization and view synthesis.
Compared with state-of-the-art methods, the proposed framework achieves reasonable manipulation and variation of the target age for real-world input images. The results demonstrate the effectiveness of the proposed method in preserving the facial identity and background details during lifelong age variation.
Proposed Methods
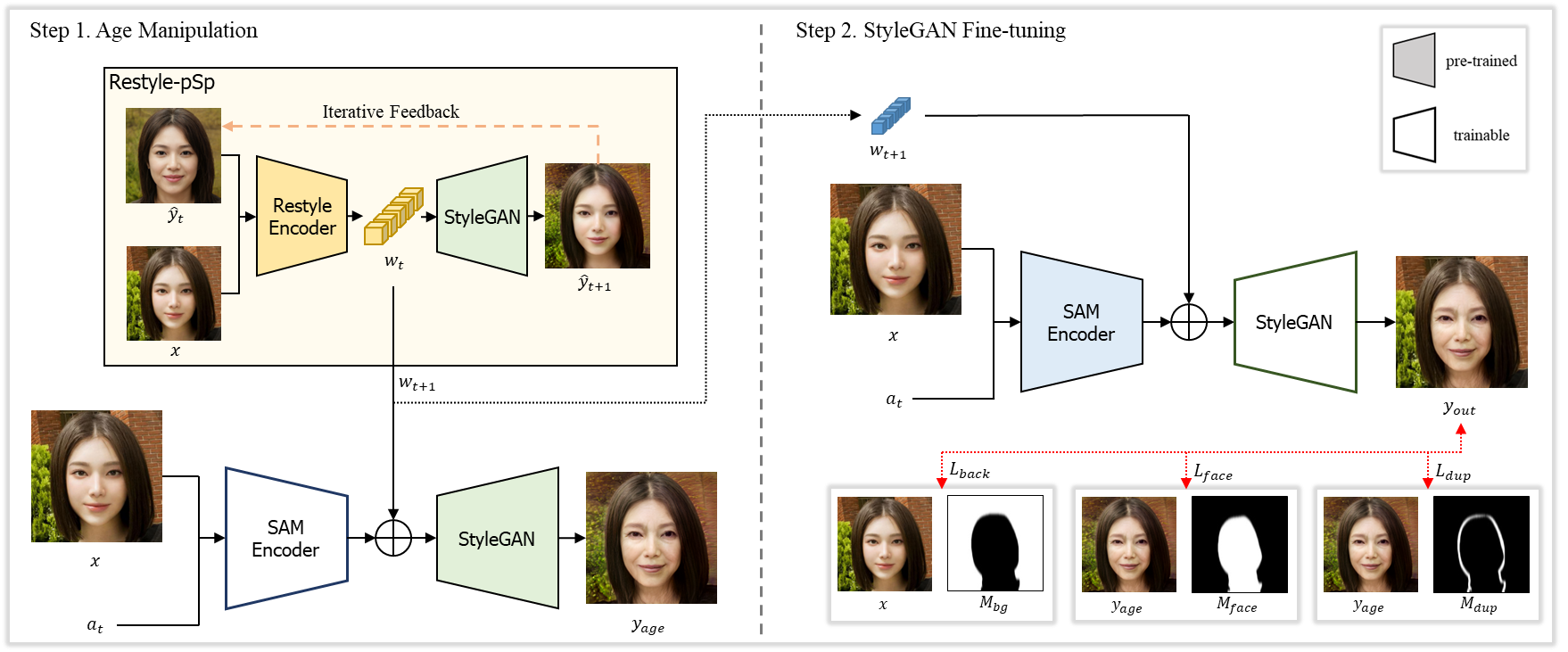
Summary of our proposed framework. The black line represents the forward pass and the red dotted line represents the fine-tuning loss functions. A color-filled box indicates a pretrained network and a box with border only represents a trainable model during each step. The Restyle-pSp architecture retrieves the latent vector wt+1 , which generates the most similar output with the input image x. The SAM encoder is then trained to produce an output yage representing the x with a targeted age at . Next, the trained SAM encoder’s weights are frozen, and the StyleGAN generator undergoes fine-tuning using the input image x, the age-manipulated image yage, and associated masks to reconstruct lost details.
Qualitative Comparison

This figure shows the results obtained by the proposed framework and existing methods. As can be seen, the existing im2im-based age manipulation method (HRFAE) struggles to manipulate lifelong age stages, especially during infancy and old age, due to its inability to edit the facial shape. The proposed framework realizes remarkable quality in terms of preserving both the identity and background of the original image. Additionally, we compared our baseline model to existing age manipulation methods to evaluate the quality of the lifelong age manipulation results.

This figure shows the image results manipulated by LATS, SAM, and the proposed framework. Again, the results of the proposed framework effectively preserve background details, enabling age manipulation on input images without requiring additional editing (such as re-combining the input’s background with the output’s face).

The additional results of the proposed framework. In this case, we trained our method using a custom Asian dataset synthesized by StyleGAN.